Common Crawl is a nonprofit 501(c)(3) organization that crawls the web and freely provides its archives and datasets to the public. Common Crawl's web... 13 KB (844 words) - 21:40, 4 March 2024 |
celebration will involve a pub crawl, often with the group splitting up but agreeing on meeting at the next location. It is a common sight in UK towns to see... 24 KB (2,428 words) - 10:15, 1 April 2024 |
weighted pre-training dataset for GPT-3 comes from a filtered version of Common Crawl consisting of 410 billion byte-pair-encoded tokens.: 9 Other sources... 54 KB (4,931 words) - 23:00, 12 April 2024 |
Data Sets". section 3.1, "Extraction Results from the November 2013 Common Crawl Corpus". 2013. Retrieved 2015-02-21. "Web Data Commons – RDFa, Microdata... 24 KB (2,854 words) - 15:15, 6 April 2024 |
 | The front crawl or forward crawl, also known as the Australian crawl or American crawl, is a swimming stroke usually regarded as the fastest of the four... 20 KB (2,801 words) - 06:31, 21 April 2024 |
Alexa, crawls run by Internet Archive on behalf of NARA and the Internet Memory Foundation, mirrors of Common Crawl. The "Worldwide Web Crawls" have been... 76 KB (7,079 words) - 22:27, 21 April 2024 |
introduction of the Pile, most data used for training LLMs was taken from the Common Crawl. However, LLMs trained on more diverse datasets are better able to handle... 13 KB (1,225 words) - 16:08, 5 April 2024 |
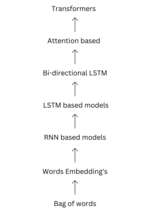 | (LLM) on large (language) datasets, such as the Wikipedia corpus and Common Crawl. This architecture is now used not only in natural language processing... 65 KB (8,163 words) - 09:37, 9 April 2024 |
 | Software Foundation. In February 2014 the Common Crawl project adopted Nutch for its open, large-scale web crawl. While it was once a goal for the Nutch... 13 KB (625 words) - 22:52, 19 February 2024 |
 | captions taken from LAION-5B, a publicly available dataset derived from Common Crawl data scraped from the web, where 5 billion image-text pairs were classified... 58 KB (5,465 words) - 05:42, 25 April 2024 |