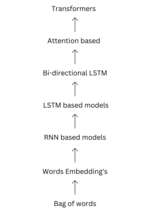
A transformer is a deep learning architecture developed by Google and based on the multi-head attention mechanism, proposed in a 2017 paper "Attention...
65 KB (8,115 words) - 17:00, 10 June 2024
Mamba is a deep learning architecture focused on sequence modeling. It was developed by researchers from Carnegie Mellon University and Princeton University...
12 KB (1,253 words) - 19:37, 15 June 2024
paper "Attention Is All You Need" which introduced the Transformer model, a novel architecture that uses a self-attention mechanism and has since become...
7 KB (542 words) - 15:45, 31 March 2024
a {\displaystyle W_{a}} is a learnable weight matrix. Transformer (deep learning architecture) § Efficient implementation Rumelhart, David E.; Mcclelland...
28 KB (2,207 words) - 17:49, 13 May 2024

supervised, semi-supervised or unsupervised. Deep-learning architectures such as deep neural networks, deep belief networks, recurrent neural networks,...
177 KB (17,583 words) - 23:11, 14 June 2024
made available for TensorFlow. Transformer (machine learning model) Attention (machine learning) Perceiver Deep learning PyTorch TensorFlow Dosovitskiy...
20 KB (2,438 words) - 17:00, 10 June 2024

used in natural language processing tasks. GPTs are based on the transformer architecture, pre-trained on large data sets of unlabelled text, and able to...
46 KB (4,093 words) - 04:56, 10 June 2024
Multimodal learning, in the context of machine learning, is a type of deep learning using multiple modalities of data, such as text, audio, or images....
7 KB (1,697 words) - 14:24, 1 June 2024
AI accelerator (redirect from Deep learning accelerator)
An AI accelerator, deep learning processor, or neural processing unit (NPU) is a class of specialized hardware accelerator or computer system designed...
53 KB (5,142 words) - 07:23, 24 May 2024
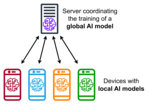
Things, and pharmaceuticals. Federated learning aims at training a machine learning algorithm, for instance deep neural networks, on multiple local datasets...
51 KB (5,963 words) - 19:17, 13 May 2024